
Een monitoring dashboard voor je Pi – Met Sampler in de terminal
Hoe meer je experimenteert met software op je Raspberry Pi, hoe groter de kans dat er af en toe iets misloopt. Een monitoring dashboard toont je in één oogopslag de meest courante problemen. In deze workshop bouwen we een commandline dashboard met Sampler.
Filip Vervloesem
Monitoring software bespaart je veel tijd bij het zoeken naar bepaalde problemen. Vaak zijn die terug te brengen tot enkele elementaire zaken: er is een schijf volgelopen, er is onvoldoende geheugen vrij, je netwerkkaart is verzadigd, enzovoorts. In een monitoring dashboard zie je meteen of al die zaken nog in orde zijn of niet. Aan monitoring apps is er geen gebrek onder Linux: zo kun je bijvoorbeeld Nagios, Zabbix of Prometheus/Grafana installeren op je Pi. Toch is dat niet per se de beste keuze, tenzij je je Pi net gebruikt om ervaring op te doen met die programma’s. Wil je snel een systeem opzetten om je Pi wat beter te monitoren, dan volstaat een eenvoudiger alternatief. Voor deze workshop hebben we gekozen om een volledig dashboard uit te werken op de commandline met behulp van Sampler. Enige ervaring met de commandline is dus wel vereist.
Sampler
In vergelijking met andere monitoring apps is Sampler erg eenvoudig van opzet. Sampler bestaat uit slechts één binary en heeft geen database nodig om data te bewaren. Ook de configuratie is erg eenvoudig, tenminste als je al uit de voeten kunt met de commandline. Je gebruikt immers allerlei vertrouwde commandline tools (zoals grep, ps of free) om het dashboard op te vullen met monitoring data. Sampler kun je misschien nog het best omschrijven als een soort top die je helemaal naar wens invult. Je kunt uiteraard gegevens over processen, cpu- en geheugengebruik tonen, maar ook het weerbericht of andere data die je van internet plukt. Zodra je dashboard klaar is, kun je het op verschillende manieren gebruiken. Is er permanent een scherm aangesloten op je Pi, dan toon je het dashboard gewoon daarop. Deel je het scherm via een kvm-switch met een andere PC? Start Sampler dan op de eerste virtuele terminal van je Pi. In geval van problemen, switch je snel even van input op de kvm-switch om te controleren of je Pi nog correct draait. En uiteraard kun je Sampler ook gewoon in een ssh-sessie opstarten. Je kunt daarvoor zelfs een alias aanmaken op een andere Linux-machine, bijvoorbeeld:
$ alias sampler='ssh -t pi@192.168.1.44 /home/pi/go/bin/sampler -c /home/pi/.sampler.yaml'
Vervolgens open je Sampler op je Pi vanaf de andere computer met:
$ sampler
Plaats de alias-regel (zonder de $) in het bestand ~/.bash_aliases op de andere machine om de alias te bewaren.
Installatie
Sampler is een relatief nieuw project en kun je dus nog niet installeren via apt. Op Github sampler releases vind je een overzicht van de beschikbare releases: versie 1.1.0 was de meest recente tijdens onze test. Maar let op: de gecompileerd versie voor Linux werkt enkel op systemen met een Intel- of AMD-cpu en niét op de Raspberry Pi! De installatie is dus iets omslachtiger. Download om te beginnen de broncode van Sampler via het bestand sampler-1.1.0.zip en pak dat uit:
$ cd Downloads $ unzip sampler-1.1.0.zip $ cd sampler-1.1.0
Installeer daarna de Go development environment en de ALSA development library:
$ sudo apt install golang libasound2-dev
Vervolgens installeer je Sampler als volgt in ~/go/bin:
$ go install
De downloads mag je nu verwijderen:
$ cd .. $ rm -rf sampler-1.1.0.zip sampler-1.1.0
Wil je Sampler opstarten zonder steeds het volledige pad in te geven? Pas dan de PATH-variabele aan door volgende regels toe te voegen aan het einde van ~/.profile:
if [ -d "$HOME/go/bin" ] ; then PATH="$HOME/go/bin:$PATH" fi
Configuratie
Sampler weigert op te starten zonder configuratiebestand: dat moet je dus meteen na de installatie aanmaken. Die configuratie schrijf je in yaml-formaat. De bedoeling is dat je een schermvullend dashboard opbouwt uit verschillende kleinere widgets. Sampler ondersteunt zes types widgets, ook wel componenten genoemd. Voor elke component configureer je vervolgens één of meerdere items. Als eerste voorbeeld nemen we de gauge-component (een horizontale voortgangsbalk). Om die correct te tonen, moet Sampler drie zaken kennen: de minimumwaarde, de huidige waarde en de maximumwaarde. Stel dat je het schijfgebruik van de root-partitie wilt monitoren in zo’n voortgangsbalk. De minimumwaarde is dan uiteraard 0, de huidige waarde is het huidige schrijfgebruik en de maximumwaarde is de schijfgrootte. Je moet dus drie commando’s schrijven die enkel de gewenste data teruggeven, zonder overbodige output. Daarvoor gebruik je het df-commando (met de m-optie toont df alle waardes in megabytes in plaats van kilobytes):
$ df -m / Filesystem 1M-blocks Used Available Use% Mounted on /dev/root 59679 2703 54521 5% /
Vervolgens knip je er de gewenste kolom uit (de tweede kolom voor de schijfgrootte of de derde voor de gebruikte ruimte):
$ df -m / | awk '{print $2}'
1M-blocks
59679
En verwijder je de legende in de eerste regel:
$ df -m / | awk '{print $2}' | sed -e 1d
59679
Maak nu een bestand ~/.sampler.yaml aan en vul daarin de gevonden commando’s in, bijvoorbeeld:
gauges:
- title: Root filesystem
rate-ms: 1000
scale: 2
percent-only: false
cur:
sample: df -m / | awk '{print $3}' | sed -e 1d
max:
sample: df -m / | awk '{print $2}' | sed -e 1d
min:
sample: echo 0
Yaml
De yaml-syntax is erg eenvoudig te gebruiken, mits je enkele regels in het achterhoofd houdt:
– gebruik steeds een dubbelepunt tussen een configuratieparameter en de waarde ervan
– spring een regel in met twee spaties om die ondergeschikt te maken aan de vorige regel
– gebruik een minteken voor een opsomming van verschillende elementen
In het voorbeeld hierboven wordt de regel ‘gauges:’ gevolgd door een opsomming van widgets van dat type (hier slechts één widget). Met ‘- title:’ maak je een nieuw widget aan, waarna je de opties voor dat widget twee spaties laat inspringen. We zien hier volgende opties:
– rate-ms: de verversingssnelheid in milliseconden (1000 = 1 seconde)
– scale: het aantal cijfers na de komma
– percent-only: zet dit op ‘true’ als je enkel de procentuele (en niet de absolute) waarde wilt zien
– cur, min en max bevatten de commando’s om data in te lezen in de voortgangsbalk
Start tot slot sampler om te testen of jouw configuratiebestand werkt:
$ sampler -c ~/.samler.yaml
Het resultaat zie je in onderstaande afbeelding. Gebruik de sneltoets q om Sampler weer af te sluiten.
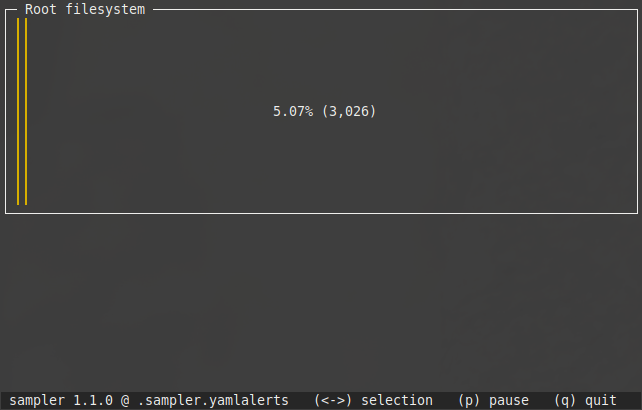
Staafdiagram
Een tweede type widget is het staafdiagram of de barchart. Daarmee kun je verschillende gegevens eenvoudig met elkaar vergelijken. Het grote verschil met de gauge is dat een barchart meestal meerdere items bevat en dat je geen minimale of maximale waardes hoeft te definiëren. Als voorbeeld visualiseren we informatie over het aantal actieve tcp-verbindingen op je Pi. Die vraag je op met volgend commando:
$ netstat -ta Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 192.168.1.44:ssh 192.168.1.11:40624 ESTABLISHED
We zijn met name geïnteresseerd in de laatste kolom, die de status van de tcp-verbinding aanduidt. Om het staafdiagram op te vullen, tel je voor elke status het aantal keer dat die voorkomt. Dat doe je met een eenvoudig grep-commando:
$ netstat -ta | grep -c LISTEN
Of iets correcter, met een awk-commando dat enkel naar de tekst in de zesde kolom kijkt:
$ netstat -ta | awk 'BEGIN{COUNT=0} $6 == "LISTEN" {COUNT+=1} END{print COUNT}'
In totaal bestaan er een tiental verschillende verbindingsstatussen, maar wij zijn enkel geïnteresseerd in de meest courante: LISTEN, ESTABLISHED, CLOSE_WAIT en TIME_WAIT. We maken dus een barchart aan met vier verschillende items:
barcharts:
- title: TCP connections
rate-ms: 1000
scale: 0
items:
- label: LISTEN
sample: netstat -ta | awk 'BEGIN{COUNT=0} $6 == "LISTEN" {COUNT+=1} END{print COUNT}'
- label: ESTABLISHED
sample: netstat -ta | awk 'BEGIN{COUNT=0} $6 == "ESTABLISHED" {COUNT+=1} END{print COUNT}'
- label: CLOSE_WAIT
sample: netstat -ta | awk 'BEGIN{COUNT=0} $6 == "CLOSE_WAIT" {COUNT+=1} END{print COUNT}'
- label: TIME_WAIT
sample: netstat -ta | awk 'BEGIN{COUNT=0} $6 == "TIME_WAIT" {COUNT+=1} END{print COUNT}'
Het resultaat zie je hier:

Sparkline
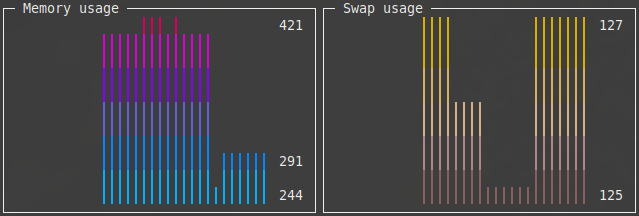
Het nadeel aan de vorige widgets is dat ze enkel de huidige status van je systeem tonen. Wil je weten of een bepaald widget een stijgende of dalende trend vertoont, dan moet je even blijven kijken naar je dashboard. Gelukkig bevat Sampler ook twee widgets die historische gegevens tonen. Het eerste widget daarvoor is de sparkline. Een sparkline geeft op vereenvoudigde wijze de trend weer van een bepaalde waarde. Je ziet niet wanneer er precies een trendbreuk was, maar het geeft je toch al een goede eerste indruk. Stel dat je het geheugenverbruik op je Pi wilt monitoren doorheen de tijd. Daarvoor kun je best twee waardes monitoren: de hoeveelheid ram en swap die momenteel in gebruik zijn. Die informatie haal je bijvoorbeeld uit de output van het free-commando:
$ free -m
total used free shared buff/cache available
Mem: 3827 55 3569 8 203 3638
Swap: 99 0 99
$ free -m | awk '/Mem:/ {print $3}'
55
$ free -m | awk '/Swap:/ {print $3}'
0
Die waardes giet je in een sparkline via volgende configuratie:
sparklines:
- title: Memory usage
rate-ms: 1000
scale: 0
sample: free -m | awk '/Mem:/ {print $3}'
- title: Swap usage
rate-ms: 1000
scale: 0
sample: free -m | awk '/Swap:/ {print $3}'
Het resultaat zie je in de afbeelding onder deze alinea. Afhankelijk van de breedte van je terminal (en de overige widgets in je dashboard) toont Sampler nu een dertig- à zestigtal samples in de sparkline. Met een interval van 1 seconde zie je dus de data van de afgelopen minuut. Wil je verder terugkijken, dan moet je de rate-ms verhogen tot pakweg 5 of 10 seconden. De sparkline toont dan data van de laatste 5 à 10 minuten. Uiteraard kun je het interval nog verder verhogen om bijvoorbeeld een uur terug te kunnen kijken.
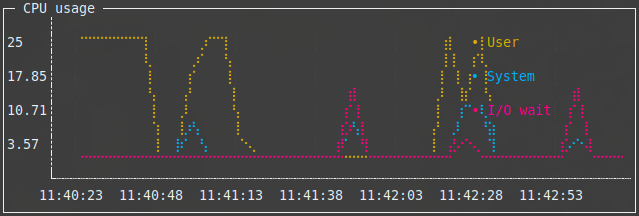
Runchart
Een runchart is het meest gedetailleerde widget dat Sampler aanbiedt. Het combineert de mogelijkheden van het staafdiagram (meerdere items tonen in één widget) met die van de sparkline (historische data tonen) én voegt daarenboven nauwkeurige timestamps toe. Als voorbeeld monitoren we het de processorbelasting op onze Pi. Heb je de top-tool al eens gebruikt, dan weet je dat die verder opgedeeld wordt in verschillende categorieën. De belangrijkste zijn us (user), sy (system) en wa (wait). Die getallen duiden respectievelijk aan hoeveel tijd de cpu spendeert aan gebruikerscode (uitgevoerd door programma’s), systeemcode (uitgevoerd door de kernel) en het wachten op input/output (zoals een trage harde schijf). Met vmstat vraag je die informatie eenvoudig op:
$ vmstat 1 2 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 58580 84068 3018840 0 0 478 407 154 174 12 2 84 2 0 1 0 0 58092 84076 3019476 0 0 512 3132 383 140 25 1 74 0 0
Standaard toont vmstat het gemiddelde processorbelasting sinds de laatste boot. Daarom voegen we de parameters 1 2 toe: vmstat toont dan 2 samples met een interval van 1 seconde. De laatste regel toont dus de processorbelasting tijdens de laatste seconde. Als je goed telt, zie je dat we de kolommen 13, 14 en 16 nodig hebben voor onze runchart. De Sampler-configuratie ziet er dan als volgt uit:
runcharts:
- title: CPU usage
rate-ms: 5000
scale: 2
legend:
enabled: true
details: false
items:
- label: User
sample: vmstat 1 2 | awk '{print $13}' | sed -e '1,3d'
- label: System
sample: vmstat 1 2 | awk '{print $14}' | sed -e '1,3d'
- label: I/O wait
sample: vmstat 1 2 | awk '{print $16}' | sed -e '1,3d'
Het resultaat zie je in deze afbeelding.
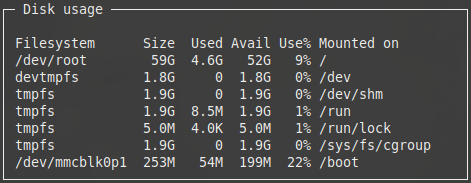
Textbox
Met een textbox widget toont Sampler gewoon de uitvoer van een commando. We geven nog snel een eenvoudig voorbeeld:
textboxes: - title: Disk usage rate-ms: 10000 sample: df -h
Dashboard finetunen
Zodra je alle widgets geconfigureerd hebt, kun je het dashboard nog finetunen. Open Sampler en gebruik de pijltjestoetsen om een widget te selecteren. Druk vervolgens op Enter en selecteer de optie Move of Resize om het widget te verplaatsen of kleiner/groter te maken via de pijltjestoetsen. Druk nogmaals op Enter om de wijzigingen door te voeren. Bij een runchart heb je nog een extra mogelijkheid, namelijk Pinpoint. Daarmee kun je met de pijltjes naar links en rechts de verschillende datapunten in het diagram selecteren (zie afbeelding hieronder). Voor elk datapunt toont Sampler dan de precieze waarde en het tijdsstip van het sample. Druk op Escape om de Pinpoint view te verlaten. Zodra je Sampler afsluit, worden de wijzigingen bewaard in jouw configuratiebestand. Je bewerkt dat bestand dus het liefst niet terwijl je Sampler hebt geopend, want zo riskeer je wijzigingen te verliezen.
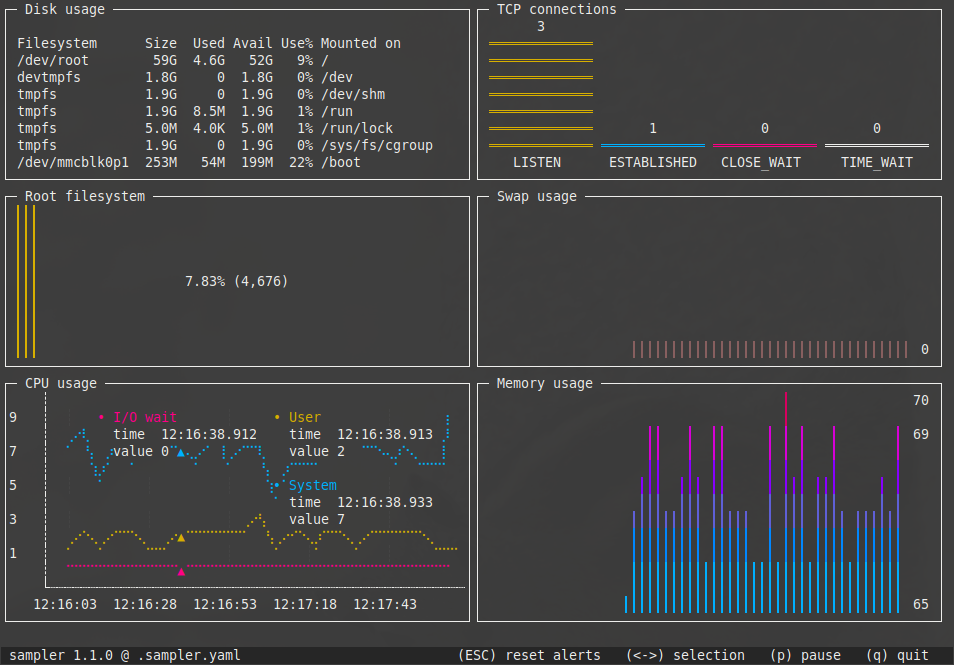
Snel aan de slag
Sampler is erg eenvoudig op te zetten voor wie al ervaring heeft met de commandline. Je leest alle informatie in via vertrouwde tools, gecombineerd met grep-, sed- en awk-commando’s. Het grote voordeel van Sampler is dat je het dashboard helemaal naar wens kunt instellen. Je kunt ook meerdere configuratiebestanden aanmaken voor verschillende dashboards, zoals een dashboard om het systeem te monitoren en een tweede met gedetailleerde gegevens over pakweg Apache of Samba. Tot slot kun je ook data van andere systemen in Sampler opnemen. Op die manier monitor je meerdere Raspberry Pi’s vanaf één overzichtelijke plaats. De README bevat een voorbeeld van hoe je dat configureert.

