
Distributed Tracing met Application Insights
De meeste developers die wel eens iets met de Azure cloud doen, zijn wel bekend met Azure Application Insights (AI). AI is onderdeel van Azure Monitor, en is met minimale configuratie te gebruiken als sink voor de logregels vanuit je applicatie. Zeker voor applicaties die op een Azure App Service Plan draaien is dit heel gemakkelijk in te richten. Je zet een verwijzing naar Application Insights in je configuratie, hengelt de .NET Logging extensions naar binnen, en klaar!
Maar een bakje met alle logregels die een applicatie heeft gegenereerd, is tegenwoordig meestal niet meer genoeg om een probleem te kunnen analyseren. In een modern applicatielandschap worden functionele processen niet door één applicatie afgehandeld, maar door een set aan gedistribueerde services. Daarom is het belangrijk om, over al deze services heen, de diagnostische data met elkaar te kunnen correleren. In dit artikel gaan we onderzoeken hoe Application Insights ons ook daarbij kan helpen.
Om goed te begrijpen wat Application Insights voor ons kan doen bij het correleren van (log)data, moeten we eerst even goed bekijken wat we eigenlijk nog meer wegschrijven naar Application Insights. Dat is namelijk niet beperkt tot logregels: ook onder andere inkomende requests en uitgaande calls (dependencies) komen terug in Application Insights.
Daarnaast kennen we een operation in Application Insights. Dit is geen item type, maar de lijm die alle items (requests, traces, dependencies) bij elkaar houdt. Een operation begint met een request, en wordt gerepresenteerd door het operation_id attribuut. En alle traces en dependencies die binnen de scope van dit request gegenereerd worden, krijgen dezelfde operation_id.
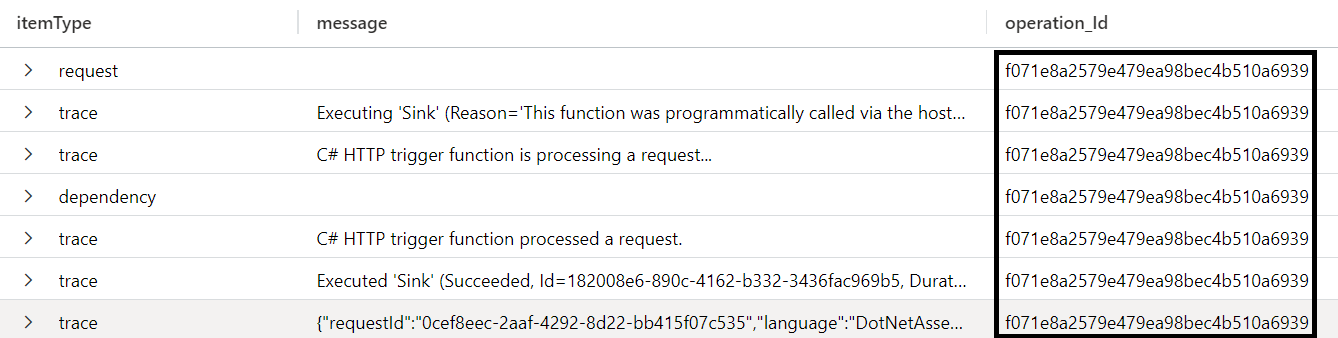
Naast de logregels die je zelf in je code invoegt, worden deze verschillende items vooral gegenereerd door de ingebakken intrumentatie in .NET runtimes, frameworks en SDK’s. Voor andere platformen en frameworks zal dat uiteraard anders zijn.
Met dit datamodel in het achterhoofd, zoeken we dus eigenlijk naar een manier om de operations in een downstream service te relateren aan operations in een upstream service. In de meest eenvoudige gevallen is dit een één-op-één relatie. Wanneer we als voorbeeld communicatie over HTTP nemen, dan hebben we at runtime een client die één call (dependency) uitvoert naar een HTTP endpoint, wat op dat endpoint leidt tot één request.
In Application Insight wordt zo’n HTTP call gemodelleerd als een parent-child relatie. We hebben aan de kant van de client een request (bijvoorbeeld omdat een browser een GET doet op een pagina), met een operation_id. De call naar de upstream service is een dependency met hetzelfde operation_id, én met een verwijzing naar het bovenliggende request: de operation_parentid van de dependency heeft dezelfde waarde als de id van het request. Aan de kant van het HTTP endpoint leidt deze call tot een nieuw request, met óók weer dezelfde operation_id. En in dit geval is de operation_parentid op het request een verwijzing naar de id van de dependency.

Dit model werkt trouwens ook over verschillende Application Insights-instanties heen. De benodigde informatie voor gedistribueerde tracing wordt in het geval van HTTP-communicatie uitgewisseld door middel van headers, dus een enkele operatie kan prima gedistribueerd zijn over meerdere Application Insights-instanties. Voor het uitvoeren van een query die alle gerelateerde telemetry van een operatie ophaalt, is het mogelijk om over meerdere instanties heen te queryen. Sterker nog: als je gebruikt maakt van de Transaction Search in de Azure portal, zal de UI zélf eventuele andere instanties uit dezelfde subscription erbij opzoeken om alle telemetry bij een operatie op te halen.
Bovenstaand model werkt heel mooi voor HTTP, en eigenlijk voor alle gevallen waarin we een één-op-één relatie hebben tussen downstream en upstream services die participeren in een operatie. Maar het is niet altijd zo simpel. Denk bijvoorbeeld aan architecturen waarin event streaming een rol speelt. Dan kun je enorme aantallen operaties hebben die allemaal een event inschieten, en verderop in de keten leeft een proces die deze events in batch verwerkt. Voor een batchproces dat 200 events per keer afhandelt, zijn er dan 200 parent operations. En slechts één operation_parentid veld. Met andere woorden: het parent-model werkt niet voor complexere ketens.
Meer en meer SDK’s gaat daarom over op een ander model, waarin een request een array van links kan bevatten naar andere operations. De nieuwe Service Bus SDK bijvoorbeeld werkt op die manier. Stel je een workload voor, bijvoorbeeld een API, die als onderdeel van een request (bijvoorbeeld een POST) een bericht op een queue moet zetten. Op deze queue luistert een Azure Function, die iets zinnigs met dat bericht moet doen. Als zowel de producer van het bericht (de API) als de consumer (de Function) naar Application Insights loggen, dan zou dat er uit kunnen zien als onderstaande afbeelding:

Je ziet hier dat de consumer van het bericht niet langer dezelfde operation_id heeft als de producer. Ook de operation_parentid verwijst nu naar zichzelf, en niet meer naar een bovenliggende dependency. Wat daarvoor in de plaats is gekomen, is een array _MS.links in de customDimensions. Hierin staat, in dit geval, één object met daarin verwijzingen naar de bovenliggende operation_id en de bovenliggende dependency. Maar het is een array, dus daar kunnen meerdere objecten in terecht komen. En dat zou het geval zijn bij een Event Hub triggered Function, die in batch meerdere events op een Hub verwerkt, die allemaal afkomstig zijn van een andere overkoepelde operatie.
En ja, ook deze nieuwe manier om gedistribueerd te correleren, wordt volledig ondersteund door de Application Insights Transaction Search, en ook hier kunnen de verschillende participanten in het proces gekoppeld zijn aan verschillende Application Insights resources.
Zoals besproken zijn een flink aantal SDK’s voorzien van out-of-the-box gedistribueerde tracing. We bespraken al hoe dit zit voor HTTP calls, en voor Azure Service Bus. Event Hub hebben we niet gezien, maar wel genoemd: ook hiervoor is dit standaardfunctionaliteit. Maar toch komt het soms voor dat je zou willen correleren over (Azure) services heen, waarbij je daar nog wat extra werk voor moet doen. Dat is bijvoorbeeld het geval bij Azure Cosmos DB.
Denk bijvoorbeeld aan een use case waarbij je Cosmos DB zou willen gebruiken als Event Store in een event-sourced systeem. Je zou dan de Cosmos DB Change Feed willen gebruiken voor event listeners om op events te kunnen reageren. En dan zou het ook mooi zijn als het proces dat leidt tot een event (de producer), te correleren is aan de processen die gaan lopen als gevolg van dat event (de listeners).
Om dit voor elkaar te krijgen moeten we er in de basis voor zorgen dat de diagnostische identifiers van het proces van de producer terechtkomen bij de consumer, zodat deze ze in het gelogde request kan toevoegen aan de array met links. In het geval van HTTP gaat dit door middel van request headers, en in het geval van Service Bus door middel van een property op het bericht. In het geval van Cosmos DB hebben we echter niet zo heel veel andere keus dan om dit als JSON property in de body van het document (ofwel het event, in onze event sourcing use case) op te slaan: er is immers verder geen metadata die van producer naar listener gaat, en die we zouden kunnen verrijken.
Dus laten we in elk event een property DiagnosticId opnemen. Hierin nemen we de Id op van de huidige Activity:
public class SomeEvent
{
public string DiagnosticId
{
get
{
return Activity.Current?.Id;
}
}
}
Deze Id is als volgt geformatteerd: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01. De 4 delen van deze string hebben elk een betekenis, waarbij deel 2 en 3 voor ons relevant zijn. Dit zijn namelijk de operation_id (deel 2) en de id (deel 3) van de huidige Activity.
Als we dit event opslaan in Cosmos, hebben we effectief de juiste diagnostische informatie ter beschikking gesteld aan de listener. De listener hoeft deze string dan alleen nog maar om te zetten in het juiste format en aan de _MS.links array toe te voegen. Verder hebben we nog wat code nodig om ervoor te zorgen dat we om kunnen gaan met meerdere events die in batch door de listener worden ontvangen:
private void SetLinks(IEnumerable<SomeEvent> events)
{
var links = events.Select(BuildLink).Where(link => link != default(OperationLink));
Activity.Current?.SetTag("_MS.links", JsonSerializer.Serialize(links));
}
private OperationLink BuildLink(SomeEvent @event)
{
var parts = @event.DiagnosticId?.Split('-');
if (parts != null && parts.Length == 4)
{
return new OperationLink(parts[1], parts[2]);
}
return default(OperationLink);
}
private record struct OperationLink(string operation_Id, string id);
Wat we doen is, voor elk event, de DiagnosticId opslitsen, waarbij we geïnteresseerd zijn in de eerder genoemde operation_id en id. Deze zetten we in een record struct en vervolgens in een array, die we gebruiken als waarde bij de key _MS.links; het geheel voegen we als tag toe aan de huidige Activity. En het framework doet de rest, wat in dit geval betekent dat deze array van links toegevoegd wordt aan de customDimensions van het request in Application Insights:

Met andere woorden: we hebben nu zelf een relatie tot stand gebracht tussen 2 processen, en we hebben dat gedaan op een manier die correct geïnterpreteerd kan worden door bijvoorbeeld de Transaction Search in Application Insights.
Er is uiteraard nog veel meer uit te zoeken aan gedistribueerde tracing in Application Insights. We hebben bijvoorbeeld weinig aandacht besteed aan hoe de relatie tussen Application Insights en de instrumentatie door middel van System.Diagnostics nu eigenlijk precies zit. Ook hebben we niet stilgestaan bij de beweging naar OpenTelemetry, wat gericht is op een open en interoperabel ecosysteem van instrumentatie en monitoring. Maar die details hoeven we ook niet te kennen, om toch gebruik te kunnen maken van de opties voor gedistribueerde tracing die Application Insights out-of-the-box biedt. En zelfs het aanhaken van je eigen spulletjes op dit model vergt niet meer dan een paar regels code.
Dus vanaf nu weten we: gedistribueerde tracing hoeft niet complex te zijn, en debugging in een gedistribueerd landschap hoeft niet moeilijker te zijn dan in een monoliet. Happy tracing!
 BIO: Annejan werkt als developer, architect en cloud consultant bij 4Dotnet, en in die rol helpt hij klanten om goede software te ontwikkelen en optimaal gebruik te maken van de cloud. Hij werkt nu ruim 15 jaar als developer. Zo’n 10 jaar geleden kwam hij in aanraking met Azure, en het enthousiasme over die grote bouwblokkendoos is sindsdien niet meer weg geweest. Hij houdt van het maken van technische oplossingen, maar ook van het delen van zijn kennis en ervaring met anderen.
BIO: Annejan werkt als developer, architect en cloud consultant bij 4Dotnet, en in die rol helpt hij klanten om goede software te ontwikkelen en optimaal gebruik te maken van de cloud. Hij werkt nu ruim 15 jaar als developer. Zo’n 10 jaar geleden kwam hij in aanraking met Azure, en het enthousiasme over die grote bouwblokkendoos is sindsdien niet meer weg geweest. Hij houdt van het maken van technische oplossingen, maar ook van het delen van zijn kennis en ervaring met anderen.

